多级缓存 - Canal 与 JVM 本地缓存的矛盾
多级缓存 - Canal 与 JVM 本地缓存的矛盾
问题背景
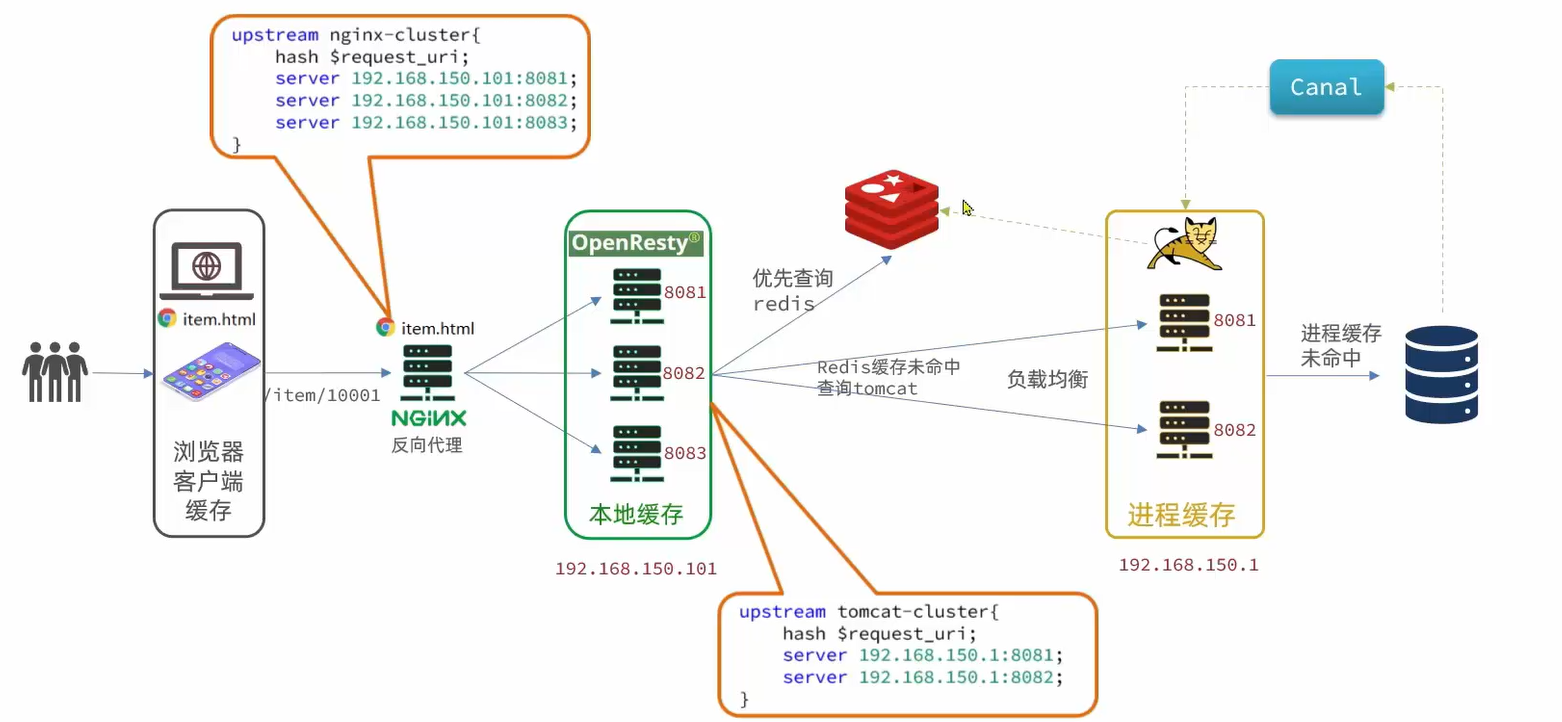
Canal Server 通过伪装为 MySQL Slave 可以监听到 MySQL Master 库日志 binary log 的变化,对 binary log 变化进行解析,Canal Server 就能知道 MySQL Master 中具体执行了什么操作,接着就可以将解析后的消息转发给 Canal Client。
在如上多级缓存的架构图中,Canal Server 有两个 Canal Client,就是商品服务的两个 Tomcat 实例。当 MySQL Master 执行了写操作后,Canal Server 监听并解析后的消息,是广播给每个 Canal Client,还是仅仅发送给其中一个呢?
实验发现,Canal Server 是以轮询的方式,将解析后的消息发送给其中一个 Canal Client 的。
其中一个 Canal Client 接收到消息后,它的消费逻辑是:
- 同步本地
Caffeine缓存 - 同步
Redis缓存
同步 Redis 缓存没什么问题,但是同步本地 Caffeine 缓存其实是有些问题的。
比如说,id 为 10001 的商品数据,已经通过 Caffeine 本地缓存到了端口为 8081 的 Canal Client 上。
当 MySQL Master 上 id 为 10001 的商品被修改后,Canal Server 能监听到修改操作,但由于 Canal Server 轮询的方式发送消息,所以可能解析后的消息恰好是轮询发给端口为 8082 的 Canal Client。
问题出现了,需要同步本地 Caffeine 缓存的是端口为 8081 的 Canal Client,但消息却发到端口为 8082 的 Canal Client 上去了,因此同步本地 Caffeine 缓存失败了。
不过,好在本地 Caffeine 缓存在多级缓存架构中的位置相对靠后,就算同步失败了,至少前面的 Redis 缓存是更新成功了,用户查询数据会先命中 Redis 缓存,从而察觉不到本地 Caffeine 缓存的同步失败。
如何解决
很自然的想法是,让 Canal Server 直接广播消息给每一个同属于一个 destinations 集群的 Canal Client。
这样的做法,显然存在两个问题:
- 同步
Redis缓存的操作会执行多次 - 本地
Caffeine缓存的数据会在所有Tomcat实例上冗余
不过这样做,确实也成功实现了同步。
但麻烦的是,Canal Server 其实并不支持广播!如果想要广播 Canal Server 的消息,还需要配合一个消息队列作为 Canal Client 来实现。
个人的一些想法,Canal 不太适合用来同步 Tomcat 集群的 JVM 本地进程缓存:
Canal Server的消息发送是轮询每个客户端,想要做到同步Tomcat集群的JVM本地进程缓存,基本就只能接入消息队列作为Canal Client来实现,而且存在数据冗余的现象。JVM本地缓存作为多级缓存中的最后一道,该缓存的利用率其实是很低的。使用Canal Server去做同步,一来比较麻烦,二来数据同步好了也不常用,三来数据利用率低了还冗余,怎么看都是性价比低。JVM本地缓存最主要的作用还是在于能够作为最后的屏障,来防止大量请求直接打到数据库导致数据库宕机。从这个角度看,前面的Redis缓存都失效了,说明网络情况可能很糟糕了,那么凭什么Canal就不会失效呢?
所以,关于如何处理 Tomcat 集群的 JVM 本地进程缓存,其实谜底就在谜面上,JVM 本地进程缓存,最好就是本地处理,不借助任何外力去完成。
个人能想到的解决方案是:
- 在
Nginx一侧做好增删改操作的负载均衡,比如确保PUT /item/10001的请求和GET /item/10001的请求可以负载均衡到同一个Tomcat实例上 - 然后本地缓存本地同步处理,最简单的,以商品服务为例,新增商品就什么都不做,删除商品或者修改商品就直接根据商品 id 删除本地缓存。
- 一旦执行了增删改以后,下次
GET /item/10001负载均衡到的Tomcat实例上,本地缓存必然是未命中,从而触发数据库查询将新数据放到本地缓存中。