synchronized 原理
synchronized 原理
本文是对于
死磕Synchronized底层实现系列的个人补充
优秀博文推荐
关于 synchronized 原理的解析众说纷纭,尤其是 jdk1.6 以后引入的相关锁优化的内容。
远古巨著 Java Concurrency in Practice 出版时间较早,因此没有锁优化的内容讲解。
:star::star::star: 深入理解 Java 虚拟机(第 3 版) 最后一个章节对锁优化的内容做了讲解,并给出了一张经典的关系图,如下:
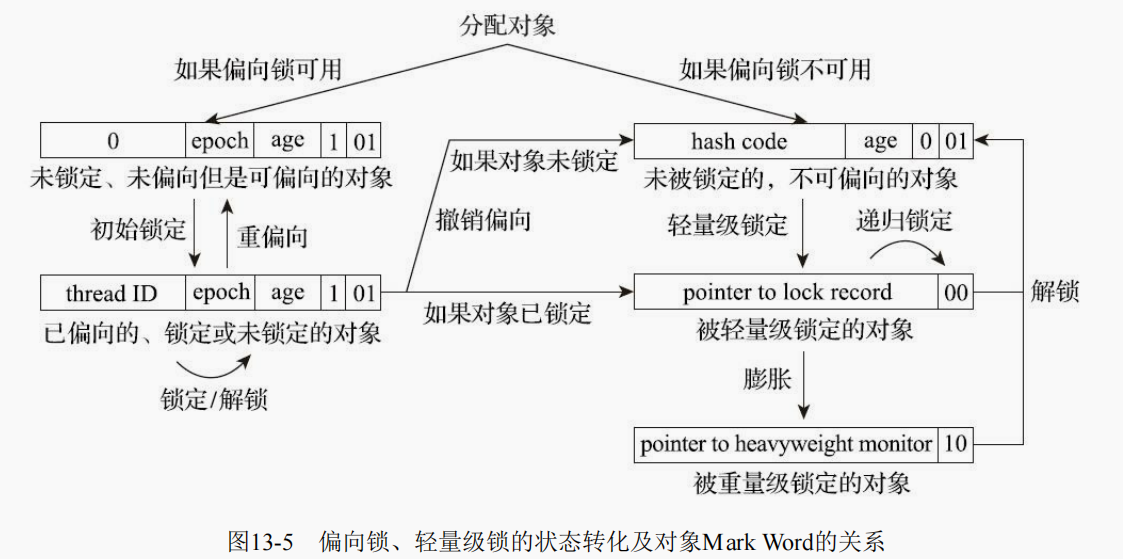
但是毕竟是 JVM 的书籍,锁优化内容的讲解相对来说还是较简略的。
下面是在网络上找到的一些讲解 synchronized 原理的优秀博文:
- :star::star::star::star::star: 死磕Synchronized底层实现:该系列总共有四篇文章,基于
Hotspot jdk8u源码讲解,至少第一篇概论是需要完全搞懂的。
- :star::star::star::star: Java锁与线程的那些事:该博文参考了死磕Synchronized底层实现系列的四篇文章,可以对照着看,作为补充。本文有一张更详细的关系图(大体是对的,但部分细节流程和源码不太一致):

:star::star::star: 难搞的偏向锁终于被 Java 移除了:适合新手入门的讲解,不涉及
Hotspot jdk8u的源码。关于批量撤销一节,原文中如下内容存在问题:
如果在距离上次批量重偏向发生超过 25 秒之外,那么就会重置在 [20, 40) 内的计数, 再给次机会
在
Hotspot Jdk8u版本下,如果批量重偏向发生后的 25 秒内,偏向撤销次数没有从 20 达到批量撤销阈值 40,此时不是重置 [20, 40) 内的计数(即重置到 20),而是直接重置为 0,这意味着批量重偏向是可以再次发生的!Hotspot Jdk8u 源码 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53enum HeuristicsResult {
HR_NOT_BIASED = 1, // 锁对象偏向模式关闭的情况:无需偏向撤销
HR_SINGLE_REVOKE = 2, // 单次偏向撤销
HR_BULK_REBIAS = 3, // 批量重偏向
HR_BULK_REVOKE = 4 // 批量撤销
};
// 递增锁对象的 klass 中的偏向撤销计数,并返回结果
static HeuristicsResult update_heuristics(oop o, bool allow_rebias) {
markOop mark = o->mark();
if (!mark->has_bias_pattern()) {
// 锁对象偏向模式关闭的情况
return HR_NOT_BIASED;
}
// 获取对象的 class 信息
Klass* k = o->klass();
// 获得当前时间
jlong cur_time = os::javaTimeMillis();
// 获得上次批量重偏向的时间
jlong last_bulk_revocation_time = k->last_biased_lock_bulk_revocation_time();
// 获取 class 中记录的偏向撤销次数
int revocation_count = k->biased_lock_revocation_count();
// 如果 偏向撤销次数 >= 批量重偏向阈值 且
// 偏向撤销次数 < 批量撤销阈值 且
// 距离上次批量重偏向的时间超过了指定时间
if ((revocation_count >= BiasedLockingBulkRebiasThreshold) &&
(revocation_count < BiasedLockingBulkRevokeThreshold) &&
(last_bulk_revocation_time != 0) &&
(cur_time - last_bulk_revocation_time >= BiasedLockingDecayTime)) {
// 重置 class 中记录的偏向撤销次数为 0
k->set_biased_lock_revocation_count(0);
revocation_count = 0;
}
if (revocation_count <= BiasedLockingBulkRevokeThreshold) {
// 原子递增偏向撤销计数
revocation_count = k->atomic_incr_biased_lock_revocation_count();
}
if (revocation_count == BiasedLockingBulkRevokeThreshold) {
// 递增后,偏向撤销计数到达批量撤销阈值
return HR_BULK_REVOKE;
}
if (revocation_count == BiasedLockingBulkRebiasThreshold) {
// 递增后,偏向撤销计数到达批量重偏向阈值
return HR_BULK_REBIAS;
}
// 单次偏向撤销的情况
return HR_SINGLE_REVOKE;
}:star::star::star::star::star: jdk8u/hotspot 源码:网站阅读体验不友好,建议直接下载完整源码,在本地进行源码的阅读
预备知识
klass, lockee, LockRecord 三者的联系
lockee 是锁对象,klass 是锁对象的类元数据信息,LockRecord 是每次加锁都会产生的一个锁记录

每次加锁,无论是偏向锁、轻量级锁还是重量级锁,都会在获取锁的线程的栈空间中添加一个 LockRecord 锁记录,并让 LockRecord 的 obj 指向 lockee。
偏向锁
偏向锁以及轻量级锁的加锁流程

偏向锁的锁重入

从偏向撤销/锁升级入口 InterpreterRuntime::monitorenter 开始分析整个偏向撤销流程
什么情况下会进入 InterpreterRuntime::monitorenter 方法?
- 获取偏向锁时/重偏向时发现锁对象已经偏向其他线程
- 轻量级锁存在竞争
- 轻量级锁膨胀中
- 已经是重量级锁
1 | IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem)) |
偏向撤销逻辑主要看 ObjectSynchronizer::fast_enter 的内容:
1 | void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) { |
重点是 Java 线程那条分支,这里可能会让人比较疑惑,当前线程明明是带着偏向撤销的目的来的,怎么 revoke_and_rebias 给当前线程来了一次重偏向的操作呢?这是因为存在批量重偏向的两种情况
- 当前线程在真正做偏向撤销操作前,还会再次检查锁对象的
epoch是否过期。如果发现过期了(之前获取偏向锁时还未过期),说明期间有其他线程先一步做了偏向撤销,并触发了一次批量重偏向(批量重偏向操作的第一步就是将Klass的epoch加 1),此时,直接将锁对象重偏向为当前线程即可。 - 当前线程的这次偏向撤销操作恰好让偏向撤销计数递增到批量重偏向阈值,因此会在 VM 线程执行完批量重偏向后,再将锁对象重偏向为当前线程。
具体还是要深入看 BiasedLocking::revoke_and_rebias 的内容,主线是递增偏向撤销计数,根据计数结果去执行单次偏向撤销/批量撤销/批量重偏向:
1 | BiasedLocking::Condition BiasedLocking::revoke_and_rebias(Handle obj, bool attempt_rebias, TRAPS) { |
revoke_and_rebias 包含了非常多种情况的处理,但是前半部分其实都是对一些特殊情况的处理,比如:
- 准备偏向撤销前再次检查
klass是否关闭了偏向模式:如果是,说明期间由于klass其他锁对象发生了偏向撤销并触发了批量撤销,从而当前锁对象可以直接 cas 对象头为无锁状态(可能成功,也可能失败,但无论失败还是成功,都直接退出。失败的情况主要是当前锁对象在批量撤销时还活跃,从而在批量撤销中被直接升级为轻量级锁)。 - 准备偏向撤销前再次检查
epoch是否过期:如果是,说明期间由于klass其他锁对象发生了偏向撤销并触发了批量重偏向,使得当前锁对象的epoch已过期,从而可以直接进行重偏向
这里我们重点关注其中的后半部分case 1和case 2。case 1表示执行单次撤销的情况,case 2表示批量撤销或批量重偏向的情况。
先来看看 case 1。
1 | // case 1 |
在 HotSpot 的内部实现中,有一系列的 VM 操作类,它们都继承自基类 VM_Operation。VM_RevokeBias 就是其中一个,它重写了基类的 doit() 方法,当调用 VMThread::execute(&revoke) 时,VM 线程就会调用 revoke 的 doit() 方法来做具体操作,其中 doit() 方法内部就调用了 revoke_bias() 方法。
1 | class VM_RevokeBias : public VM_Operation { |
接下来重点分析一下 revoke_bias 方法。revoke_bias 方法一般是 VM 线程来执行,该方法虽然名字上看是叫撤销偏向,但却接收一个 allow_rebias 参数:
- 该参数绝大多数情况下都是
false,比如上面的case 1中VMThread::execute(&revoke)去做单次撤销,以及后面的case 2中的VMThread::execute(&bulk_revoke)去做批量撤销。allow_rebias == false的情况下revoke_bias方法必然是去执行偏向撤销的操作。 - 一般为
true只存在一种情况,与case 2中的VMThread::execute(&bulk_revoke)去做批量重偏向有关,后面会提到。
1 | static BiasedLocking::Condition revoke_bias(oop obj, bool allow_rebias, bool is_bulk, JavaThread* requesting_thread) { |
对于 case 1 的场景而言,revoke_bias 只存在单次偏向撤销的情况:
- 如果锁对象偏向的线程 A 已经不存活,那么就直接将锁对象设置为无锁状态
- 如果锁对象偏向的线程 A 还存活,但是并不活跃(正在持有锁执行同步代码块),也是直接将锁对象设置为无锁状态
- 如果锁对象偏向的线程 A 存活且活跃,锁对象将直接升级为轻量级锁(这里处理时,考虑了锁重入的情况)
我们再回过头来看 case 2 的情况,也就是批量撤销或批量重偏向的情况:
1 | // case 2 |
在 revoke_and_rebias 方法中执行了一次 update_heuristics 来递增偏向撤销的计数,该该方法的返回值很关键:
1 | HeuristicsResult heuristics = update_heuristics(obj(), attempt_rebias); |
如果偏向撤销计数达到了批量撤销的阈值,那么返回值就是 HR_BULK_REVOKE
如果偏向撤销计数达到的是批量重偏向的阈值,那么返回值就是 HR_BULK_REBIAS
在构造 VM_BulkRevokeBias 对象实例时,传入的第三个参数 (heuristics == HR_BULK_REBIAS) 就能够根据 update_heuristics 返回值的不同,最终让 VM 线程去执行批量撤销或者批量重偏向。
1 | // VM_BulkRevokeBias 继承了 VM_RevokeBias,从而也是 VM_Operation 的子类 |
接下来重点分析一下 bulk_revoke_or_rebias_at_safepoint 方法。bulk_revoke_or_rebias_at_safepoint 在命名上就已经反映了,该方法一般是 VM 线程来执行。
1 | static BiasedLocking::Condition bulk_revoke_or_rebias_at_safepoint(oop o, |
上面的批量重偏向以及批量撤销操作中,都涉及到了一个遍历线程栈,所有目前正在“活跃”的类型为 Klass 的偏向锁对象的操作,为什么我这里的“活跃”打了个引号呢?
先下定义:真正的活跃状态指的是,偏向锁对象目前处在锁定状态,也即所偏向的线程正在执行同步代码块的状态。
但其实存在一些偏向锁对象,它并没有在执行同步代码块,却也被批量重偏向和批量撤销操作处理了。
举个简单的例子,线程 B 去访问偏向锁,发现偏向的是线程 A,即使线程 A 此时没有在执行相应的同步代码块,即在线程 A 的线程栈中找不到关联偏向锁的 LockRecord,但由于只要从偏向锁的入口进入就会在相应的线程栈中创建一个 LockRecord 并与偏向锁关联,所以线程 B 的栈中会存在一个关联偏向锁的 LockRecord,导致偏向锁明明没有被锁定却会被处理!
1 | CASE(_monitorenter): { |
总结一下,批量重偏向以及批量撤销可能“误伤”了一些不在锁定状态的偏向锁对象,这些偏向锁对象虽然有相应的 LockRecord,但实际上并没有被所偏向的线程锁定:
- 批量重偏向的误伤:未锁定的锁对象也更新
epoch,而不是让它过期 - 批量撤销的误伤:未锁定的锁对象被撤销偏向,被修改为无锁状态
总的来说,这种“误伤”也无伤大雅。
想要避免“误伤”的话,其实源码里面略作改动即可,也即遍历所有线程栈,如果找到一个 LockRecord 其 obj 指向了一个偏向锁对象(对象为 Klass 类型)后,额外再到偏向锁对象所偏向的线程的栈中再检查是否存在关联的 LockRecord。但这样的话,就变成了三层循环,可能导致性能的下降。
至此,我们总算是将偏向锁撤销的完整流程走通了。
为什么偏向撤销一般是需要在 safepoint 期间来完成的?
假设偏向锁对象正在被线程 A 使用,线程 B 此时也来获取锁,在线程 B 的视角下,它知道目前锁对象已经偏向了线程 A,需要进行偏向撤销操作。
- 偏向撤销操作需要根据锁对象是否活跃来做不同的处理。
然而线程 B 根本无法确定锁对象是否活跃。要确定锁对象是否活跃,线程 B 必须要访问线程 A 的栈空间看看有没有对应的LockRecord,这是不可能的,JVM 中每个线程的栈空间都是线程私有的。 - 就算线程 B 开了天眼知道锁对象是活跃的,即线程 A 正在执行同步代码块,线程 B 也无法执行活跃情况下的偏向撤销处理。
偏向锁活跃,此时要做偏向撤销是升级为轻量级锁:锁对象的markword需要设置为指向线程 A 中的第一个LockRecord的地址。但是线程 B 不可能访问线程 A 的栈空间,也就无法得到线程 A 中的第一个LockRecord的地址。
于是线程 B 只能偏向撤销的操作交给 VM 线程来完成。
到了 safepoint 期间,所有 Java 线程都停止工作,VM 线程开始活动。
VM 线程可以访问所有 Java 线程,自然就可以到线程 A 中去检查栈中是否有指向该偏向锁对象的 LockRecord,如果有就说明偏向锁活跃,线程 A 还在执行同步代码块,否则就是不活跃,线程 A 已经释放了偏向锁。根据活跃状态的不同,VM 线程就可以去做不同的处理了:
- 偏向锁对象活跃,VM 线程此时找到线程 A 的栈中最早的那个
LockRecord,将其displaced markword设置为无锁状态,将其他的LockRecord的displaced markword设置为NULL,然后将该LockRecord的地址设置到偏向锁对象的markword中去,从而直接完成偏向锁到轻量级锁的升级。注意,这里的处理是兼顾了锁重入的情况。 - 偏向锁对象不活跃,或者偏向线程已死的情况,直接将偏向锁对象的
markword设置为无锁状态,从而完成偏向锁到无锁状态的转换。
批量重偏向
每次执行偏向撤销,都会将偏向锁对象所属的 Klass 类信息中的 revocation_count 加一。
一旦 revocation_count 到达 BiasedLockingBulkRebiasThreshold 批量重偏向阈值(一般是 20),就执行批量重偏向操作。
批量重偏向这个命名具有一定的迷惑性,初学者容易误以为,批量重偏向是立即完成的。
其实稍微想一下,就知道批量重偏向是不可能立即完成的,我们无法预知未来!
从批量重偏向的实际操作逻辑来看,其实真正将某个偏向锁的 markword 中的 threadId 偏向于新线程,是要等到下次线程来获取偏向锁时才发生的,因此批量重偏向,可以理解为是批量打上可重偏向标记。
Klass 可能有非常多的对象实例,在批量重偏向后,那些在批量重偏向时不活跃的偏向锁对象,就被打上一个可重偏向标记。
如果一个偏向锁对象带有该标记,就说明该对象目前一定是没有线程在使用的,即没有线程正在执行相应的同步代码块。这样下次有线程来获取该对象时,看到有可重偏向标记,就可以放心的执行 cas 操作,将自己的线程 id 设置到该对象的 markword 中来完成重偏向,无需担心是否会影响到其他线程。这里也可能是重偏向给自己,但无论是重偏向给谁,重偏向发生过后,被打上的可重偏向标记也随着 cas 操作被清除掉了。
至于那些批量重偏向时还活跃的对象,由于所偏向的线程还在使用它们,因此它们本就不具备可重偏向的条件,自然就不会被打上可重偏向的标记,后续如果其他线程来访问,应该将进入偏向撤销的逻辑。
“批量重偏向是为那些批量重偏向时不活跃的偏向锁对象,打上一个可重偏向标记”,这其实一种便于理解的说法。实际上,批量重偏向主要做了两件事:
- 先将
Klass类信息中的epoch加一。 - 然后找出
Klass所有目前正在“活跃”的偏向锁对象,让其epoch与Klass类信息的epoch保持一致。
可以看到,其实批量重偏向压根就没有去操作那些不“活跃”的偏向锁对象,而是反过来去操作那些“活跃”的偏向锁对象。但正因为没有操作,所有这些不活跃对象的 epoch 肯定是过期的,与 Klass 类信息中的 epoch 不一致的。这种不一致,其实是就相当于是一种可重偏向标记。
当下次有线程来获取该对象的偏向锁时,会先检查 epoch 是否过期,如果已过期,则认为是打上了可重偏向标记的不活跃对象,直接进行 cas 操作更新 epoch 和 threadId。
批量撤销
针对于某个 Klass 的批量重偏向发生后,系统就会记录这个批量重偏向的时间,如果这个 Klass 的对象实例,在接下来的指定时间内 BiasedLockingDecayTime(一般是 25 秒),发生了多次偏向撤销操作,导致 revocation_count 超过了批量撤销的阈值 BiasedLockingBulkRevokeThreshold(一般是 40),此时就会进行批量撤销。
一般来说,revocation_count 在批量重偏向后为 20,如果在批量重偏向后的 25 秒内,到达了 40,就触发批量撤销操作;否则就重置 revocation_count 为 0,从而为下次批量重偏向提供可能。
批量撤销主要做了两件件事:
- 标记
Klass为不可偏向,具体是修改Klass中的prototype_header为不可偏向模式。 - 找出
Klass所有目前正在“活跃”的偏向锁对象,逐个执行偏向撤销操作- 真正活跃的处于锁定状态的,会升级为轻量级锁
- 实际不活跃的未处于锁定状态的,会修改为无锁
批量撤销后,如果创建了 Klass 的新对象实例,那么这些新对象实例创建出来就是不可偏向的无锁状态,即 markword 的后三位是 001,后续线程来加锁时是直接加轻量级锁,而不会进入加偏向锁的逻辑。
而对于那些批量撤销前,已经创建出来的 Klass 的旧对象实例:
- 如果对象实例已经是无锁/轻量级锁/重量级锁状态,根本不会受到批量撤销的影响。
批量撤销本质是对处于偏向状态的那些对象,逐个执行单次偏向撤销操作! - 如果对象实例是偏向锁状态,此时具体可分为两类:
- 批量撤销时正“活跃”的对象,遍历所有 Java 线程栈空间能找到对应
LockRecord的:如上面所说,真正活跃的会升级为轻量级锁,实际不活跃但被误以为活跃的,会修改为无锁 - 确实不活跃的对象,遍历所有 Java 线程栈空间都找不到对应的
LockRecord的,这一类对象在重新活跃时,可能受到影响:epoch没过期且偏向的是当前线程,则不受影响,后续直接进入同步代码块,锁对象依然是偏向锁- 其他情况,包括
epoch过期,匿名偏向状态,或者不是偏向当前线程的,会直接cas关闭锁对象的偏向模式,置为无锁状态
- 批量撤销时正“活跃”的对象,遍历所有 Java 线程栈空间能找到对应
题外话:批量撤销时,为什么不干脆再把那些确实不活跃的偏向锁对象也一并处理为无锁呢?
个人认为,可能是处于以下的考虑:
主要原因是,“活跃”的偏向锁对象容易定位到。
每个“活跃”的偏向锁对象必然在某个 Java 线程的栈中存在一个LockRecord与之关联,遍历 JVM 所有线程栈中的LockRecord,如果某个LockRecord的obj字段指向了给定Klass类型的对象,那么这个对象就是“活跃”的偏向锁对象。
而确实不活跃的偏向锁对象就麻烦了,无法通过LockReocrd机制来指引,要找到这些类型为Klass的对象实例可能需要遍历整个堆,这无疑是非常耗时的,会极大延长批量撤销时的safepoint时间!确实不活跃的偏向锁对象可能非常多,且可能以后都不会使用了,在宝贵的
safepoint时间下立即对它们处理性价比不高。
要知道,在开启偏向锁的情况下,每个 Java 对象被创建时都默认是匿名偏向状态,可见不活跃的偏向锁对象一定是很多的!但其中绝大多数可能以后都不会使用了,在宝贵的safepoint时间下立即对它们处理性价比不高,让这些不活跃对象后续重新活跃时再处理,是种高效且自然的做法。确实不活跃的偏向锁对象虽然在批量撤销中没有直接处理,但它们都隐式地带上了一个不活跃的标记,这个标记的存在保证了不活跃对象后续重新活跃时,再进行偏向撤销操作会非常容易。
一般的偏向撤销操作是需要等到safepoint去执行的。如果能确定锁对象是不活跃的,那么偏向撤销操作其实根本就无需等到safepoint,直接cas将锁对象的markword设为无锁状态即可。
恰好,批量撤销后,所有活跃的偏向锁对象都在批量撤销期间已被处理,JVM 中剩余的Klass偏向锁对象都必然是不活跃的!这就是所谓的隐式地带上了一个不活跃的标记。
既然不活跃对象在非safepoint的情况下也能很方便处理,那何必浪费宝贵的safepoint时间呢,而且重新活跃再处理,不活跃就一直不处理,显然是更高效的做法。
出于类似的考虑,批量重偏向中也是处理那些活跃的偏向锁对象。
题外话:批量撤销可不可以只将 Klass 标记为不可偏向就结束,而不去逐个撤销那些活跃的偏向锁对象呢?这样批量撤销时的 safepoint 就更短了。
如果不去逐个撤销那些活跃的偏向锁对象,那么批量撤销后 JVM 中剩余的 Klass 偏向锁对象有可能是活跃的,也有可能是不活跃的,此时任意一个对象后续需要偏向撤销时,由于不确定它是否是活跃的,就需要等到 safepoint 才能去完成偏向撤销操作。
因此,批量撤销所在的 safepoint 时间可能是短了,但是省下来的时间其实是被转移到了后续多个 safepoint 中了。与其让将这些偏向锁对象放到后续的往往是多个 safepoint 来分批做偏向撤销,倒不如直接就在这次 safepoint 期间就批量进行偏向撤销。
轻量级锁
轻量级锁的锁重入

为什么 Hotspot 选择在线程栈中添加多个 LockRecord 来表示锁重入?
一个简单的方案是将锁重入次数记录在对象头的
mark word中,但mark word的大小是有限的,已经存放不下该信息了。
另一个方案是只创建一个Lock Record并在其中记录重入次数,Hotspot没有这样做的原因我猜是考虑到效率有影响:每次重入获得锁都需要遍历该线程的栈找到对应的Lock Record,然后修改它的值。
目前 Hotspot 的用多个 LockRecord 表示锁重入的做法,每次获取锁和释放锁,一样是需要遍历线程的栈去找对应的 LockRecord。
个人猜测,可能和效率关系不大,实现方便应该是主要因素:特别是要考虑轻量级锁升级到重量级锁的逻辑。
ObjectSynchronizer::slow_enter 补充分析
前面分析偏向锁撤销流程时,我们简单分析过 fast_enter 和 slow_enter,但重点是放在 fast_enter 上。现在我们重点看 slow_enter。
进入 slow_enter 存在非常多种情况,我们关注那些具有代表性的,能串通锁升级流程的情况:
- 锁一开始是偏向锁,偏向于线程 A,当前线程 B 获取偏向锁失败,执行偏向撤销
- 线程 B 执行偏向撤销时,线程 A 已不存活或未在同步代码块内,线程 B 偏向撤销将锁变为无锁状态,然后进入
slow_enter - 线程 B 执行偏向撤销时,线程 A 在同步代码块内,线程 B 偏向撤销将锁变为轻量级状态,然后进入
slow_enter
- 线程 B 执行偏向撤销时,线程 A 已不存活或未在同步代码块内,线程 B 偏向撤销将锁变为无锁状态,然后进入
- 锁一开始是轻量级锁状态,被线程 A 持有,当前线程 B 尝试以轻量级锁方式获取锁,失败,跳过偏向撤销流程,进入
slow_enter - 锁一开始是轻量级锁状态,被线程 A 持有,线程 C 来获取轻量级锁失败,跳过偏向撤销流程,进入
slow_enter执行锁膨胀。当前线程 B 尝试以轻量级锁方式获取锁,由于锁处于膨胀中,故失败,跳过偏向撤销流程,进入slow_enter - 锁一开始是重量级锁状态,被线程 A 持有,当前线程 B 尝试以轻量级锁方式获取锁,由于锁已经膨胀为重量级锁,故失败,跳过偏向撤销流程,进入
slow_enter
1 | void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) { |
现在我们来分析一下 slow_enter 方法:
1 | void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) { |
slow_enter 很简短,主要逻辑是:
- 先最后再检查一下,是否实际上不存在多线程竞争的情况,是的话,直接处理并返回,避免锁膨胀为重量级锁
比如code 1处的无锁情况,典型情况是:一开始是偏向锁,偏向于线程 A,当前线程 B 获取偏向锁失败,执行偏向撤销操作时,线程 A 已不存活或未在同步代码块内,线程 B 偏向撤销将锁变为无锁状态,线程 B 走到code 1去获取锁时实际上不存在竞争情况 - 前面没有返回的话,说明锁存在多线程竞争,此时将当前线程最开始申请的
LockRecord的header标记为unused,表示该LockRecord对应的加锁情况是,锁膨胀后拿到重量级锁Monitor去加锁的。这个unused标记在解锁时将会被用到,用以和其他情况做区分。
:question: slow_enter 中 else if 分支,也即 code 2 处是处理实际上不存在多线程竞争的一种情况,轻量级锁的锁重入的情况,但我实在是想不到哪些情况能进入该分支……只能猜测或许是一些非常规情况(如在某些不恰当的时机调用了 Object#hashCode 方法)。
并发程序的运行情况往往很复杂,会有很多意想不到的情况,想要完全考虑周全是很困难的,另外验证并发程序的正确性也是一件麻烦事。
因此从并发编程实践的角度来说,就算诸如上面的 else if 分支处理是多余的,那无非也就多了一些冗余的代码,换来的好处却是显而易见的:
- 首先就是能减少程序员并发编程时的很多心智负担,一来不用去考虑一些边边角角的情况,二来能对并发程序进行划分,为下一阶段的并发程序提供一个隐式的断言。
- 另外如果此类的分支真的命中,可以提高并发程序的性能或安全性。
锁释放失败入口 InterpreterRuntime::monitorexit 分析
1 | CASE(_monitorexit): { |
以上是锁释放流程。可以看到,进入锁释放失败入口 InterpreterRuntime::monitorexit 只可能存在两种情况:
- 线程 A 初次锁定轻量级锁
- 线程 B 来获取轻量级锁导致锁膨胀,在锁膨胀中途,线程 A 想要以轻量级锁方式释放锁,失败
- 线程 B 来获取轻量级锁导致锁膨胀,锁膨胀为重量级锁后,线程 A 想要以轻量级锁方式释放锁,失败
- 线程 A 在锁膨胀后的所有加锁,也即使用重量级锁 Monitor 加锁,想要以轻量级锁方式释放锁,失败
InterpreterRuntime::monitorexit 的代码很简短,主要是调用了 ObjectSynchronizer::slow_exit,
1 | IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorexit(JavaThread* thread, BasicObjectLock* elem)) |
ObjectSynchronizer::slow_exit 调用的是 ObjectSynchronizer::fast_exit,fast_exit 最后锁膨胀得到 Monitor 后再调用其 exit 方法解锁。
1 | void ObjectSynchronizer::slow_exit(oop object, BasicLock* lock, TRAPS) { |
重量级锁
为什么需要一个膨胀中的状态
1 | // Why do we CAS a 0 into the mark-word instead of just CASing the |
其实注释已经说得非常清楚了,我结合自己的理解翻译一下:
为什么我们要将膨胀中状态(即 0) CAS 到锁对象的 markword 中,而不是直接将 markword 从指向 LockRecord 的地址值 CAS 到指向重量级锁 Monitor 的地址呢?
考虑线程对轻量级锁进行最后一次解锁时的情况,它会试图使用 CAS 将 LockRecord 的 displaced mark word 中存放的 lockee 的 markword 的无锁状态,重新挪回到 lockee 中去,从而 lockee 恢复为无锁状态。
回忆一下,锁对象原始 markword 头部信息可能存放在哪些位置:
(a) 锁对象头部,此时处于无锁状态
(b) 栈空间中与锁对象关联的第一个 LockRecord 的 displaced mark word 中
(c) 重量级锁 Monitor 的 header 中
JDK1.6 以前,synchronized 只有 Monitor 重量级锁,彼时如果对象已经加锁了,想要获取重量级锁对象的原始 markword 头部信息,就需要到 (c) 中去获取。
后续引入轻量级锁后,如果对象已经加轻量级锁了,想要获取轻量级锁对象的原始 markword 头部信息,就要到 (b) 中获取;当然如果对象加的是重量级锁,获取重量级锁对象的原始 markword 头部信息,依然是到 (c) 中去获取。
为了保证轻量级锁升级到重量级锁后,依旧能够正确地获取原始 markword 头部信息,锁膨胀时,就必须将原来存放在 (b) 中的原始 markword 头部信息,复制一份放到 (c) 中去,并保证这个膨胀升级过程中原始信息如 hashCode 的不变性。
如果不设置一个膨胀中的状态,就会无法保证膨胀升级过程中的原始信息不变性,考虑如下情况:
- 线程 A 调用了
hashCode - 线程 A 进行轻量级锁的初次锁定
- 线程 B 尝试获取轻量级锁,开始进行锁膨胀,锁膨胀至少包含下面的操作:
3.1 将锁对象的markword从指向LockRecord改为指向Monitor
3.2 将LockRecord中的原始头部信息,复制到Monitor的header中去 - 由于整个锁膨胀不是原子的,假设线程 B 执行完 (3.1) 后,线程 A 再次调用了
hashCode
此时,锁对象的markword表示对象已经是重量级锁状态,因此线程 A 回到Monitor中去获取hashCode,但线程 B 还未执行 (3.2),因此返回必然是错误值。 - 等到线程 B 执行完 (3.2) 以后,线程 A 再次调用
hashCode就可以拿到正确结果了。
注释将这种 hashCode 短暂不一致的情况称为 hashCode 值的闪烁现象。即使调转 (3.1) 和 (3.2) 的顺序,闪烁现象一样存在!
注释提到的破坏不变形的情况更加糟糕!线程 B 执行了 (3.1) 但还没来得及执行 (3.2) 时,线程 A 释放了锁,此时就是重量级锁的释放流程,有可能将 Monitor 中错误的 header 放回到锁对象的 markword 中。这样释放锁后,对象的对象头部不仅 markword 信息可能是错的,还可能没有正确地被设为无锁状态,甚至这种错误信息还是长期存在的。
为了应对这种情况,锁膨胀加入了一个膨胀中的(0)状态:
3.1 将对象的 markword 从指向 LockRecord 改为膨胀中的 0 状态
3.2 将 LockRecord 中的原始头部信息,复制到 Monitor 的 header 中去
3.3 将对象的 markword 从膨胀中的 0 状态改为指向 Monitor
线程 B 执行了 (3.1) 但还没来得及执行 (3.2) 时,线程 A 释放了锁,此时线程 A 发现锁处于膨胀中(0)状态,就会进入自旋忙等,直到线程 B 执行了 (3.2) 乃至 (3.3) 后,线程 A 才能够真正去做重量级的锁释放。
关键在于:只要锁处于膨胀中(0)状态,那么最终要换回到对象中的原始 markword 头部信息就是稳定的。
Monitor 机制下的 wait/notify 执行过程
1 | public class WaitNotifyTest { |
简单分析一下上述代码的执行过程:
- 首先线程 A 获取到 lock 锁,此时是轻量级锁状态,获取到锁后线程 A 开始执行同步代码块内容
- 线程 B 尝试获取 lock 锁,但锁已经被线程 A 占用,此时线程 B 进行锁膨胀操作,膨胀后发现锁依然被线程 A 占用,封装线程 B 为
ObjectWaiter插入到Monitor.cxq队列的队首,并park进入阻塞状态。 - 线程 A 执行到
lock.wait()时,先将线程 A 封装为ObjectWaiter并添加到Monitor.waitSet中,然后进行锁释放操作,首先将Monitor.owner置为NULL,然后找到Monitor.cxq中正在阻塞等待的线程 B 的ObjectWaiter从而可以唤醒线程 B,最后park进入阻塞状态。 - 线程 B 被唤醒后获得锁,执行同步代码块内容
- 线程 B 执行到
lock.notify()时,会将Monitor.waitSet中存放的线程 A 的ObjectWaiter移动到Monitor.entryList中,而不会立刻唤醒 - 线程 B 继续执行同步块中的剩余代码,执行完毕后释放锁,首先将
Monitor.owner置为NULL,然后找到Monitor.entryList中阻塞等待的线程 A 的ObjectWaiter从而可以唤醒线程 A - 线程 A 被唤醒后获得锁,执行剩余的同步代码块内容,执行完毕后释放 lock 锁
搁浅现象
当竞争发生时,选取一个线程作为
_Responsible,_Responsible线程调用的是有时间限制的park方法,其目的是防止出现搁浅现象。
:question: 实在想不明白搁浅现象是个什么现象,下面贴一段 ObjectMonitor::exit 方法定义前的一段注释,后续有能力再回头研究…
1 | // 1-0 exit |
重量级锁的释放 ObjectMonitor::exit 分析
1 | void ATTR ObjectMonitor::exit(bool not_suspended, TRAPS) { |
exit 方法中 code 1 及以前的代码必然是单线程执行的,不存在并发情况,因为锁是独占的,只有获取锁的那个线程才能执行到 exit 方法来做锁释放逻辑。
但这并不意味着,整个 exit 方法都是不存在并发的,其实 code 1 之后的代码都是要考虑并发情况的,其中:
code 1释放锁之后的代码一直到code 3这几行代码是多个线程并发执行的情况,code 3中的cas操作也说明了这一点。code 4的代码不存在多线程并发执行的情况,其中主要考虑的是_cxq的并发安全。因为唤醒可能会涉及到对_cxq队列的一些操作,但同时可能有大量的其他线程获取锁并阻塞,这些线程也需要操作_cxq:向_cxq中插入自己的ObjectWaiter。
code 1 处当前线程一旦将 owner 设置为 NULL 后,锁其实就已经释放掉了,此时如果有新的线程来访问同步代码块,就立刻可以 cas 获得锁。
- 假设最初是线程 A 来持有锁,它在
code 1处将owner为NULL从而释放了锁。 - 然后线程 B 来访问同步代码块,发现
owner为NULL,因此获得锁,获得锁以后,它很快执行完了同步代码块的内容,它也在code 1处将owner为NULL从而释放了锁。 - 此时线程 A 和线程 B 可能同时处在
code 2的位置想要继续往下执行,这就出现了并发
code 2 处:
- 如果已经没有等待的线程,那么并发的线程 A 和线程 B 都直接退出,无需进行后面
code 4的唤醒操作,这个很好理解。 - 如果还存在等待的线程,那么就需要做后面
code 4的唤醒操作。假设是线程 A 完成了后续的唤醒并选定了假定继承人,从而_succ可能就非NULL,这时候线程 B 并发执行code 2,发现_succ非NULL就可以直接退出。
code 3 处:
- 如果当前已经有其他线程,比如新线程 C 获取到了锁,那么线程 A 和线程 B 将在
code 3处 CAS 失败直接退出,无需后面的唤醒操作。这个很好理解,到时后线程 C 释放的时候,它来负责唤醒。 - 如果当前没有其他线程获取到锁,此时为了避免唤醒多个线程,让线程 A 和线程 B 去
cas竞争,从而保证只有一个线程可以进入后续的code 4去做唤醒。
为什么要保证只有一个线程进入 code 4 呢?来看一下 ObjectMonitor::ExitEpilog 的代码就懂了:
1 | void ObjectMonitor::ExitEpilog (Thread * Self, ObjectWaiter * Wakee) { |
多个线程来唤醒,就有多个线程去执行 ExitEpilog 方法,从而存在线程安全问题。
假设线程 A 和线程 B 都可以进入 code 4 执行 ExitEpilog 方法
- 线程 A 执行
ExitEpilog方法将owner设置为NULL释放锁,此时新线程 D 来访问同步代码块获得了锁,执行同步代码块 - 线程 D 还未执行完同步代码块。线程 B 也执行
ExitEpilog方法将owner设置为NULL释放锁,明明是线程 D 持有锁,可却让线程 B 去释放了,此时如果新线程 E 来访问同步代码块,也能获得锁,从而线程 D 和线程 E 都在执行同步代码块
除此 ExitEpilog 方法之外,唤醒还包括了一系列对 _cxq 和 _EntryList 的操作,这些操作在并发执行时也可能存在线程安全问题。
轻量级锁重入后,锁膨胀并再次发生多次重量级锁重入后,是什么情况
假设线程 A 初次锁定轻量级锁,然后又发生了一次轻量级锁重入,而后线程 B 来获取轻量级锁导致锁膨胀,膨胀后的情况如下:

膨胀后,线程 A 再次获取锁,发生一次重量级锁重入,情况如下:

重量级锁重入的这次加锁对应的 LockRecord 3,其 displaced mark word 被标记为 unused。
另外 Monitor 的变化是:
_recursions加 1owner从指向LockRecord 1变为指向线程 AOwnerIsThread从 0 置为 1
后续如果继续有重量级锁重入,只需要递增 _recursions 即可,不再需要修改 owner 和 OwnerIsThread。
何时重量级锁对象恢复到无锁状态
你可能注意到了,重量级锁对象的释放,似乎只是将 Owner 置为 null 就结束了。那何时重量级锁对象会恢复到无锁状态呢?下面来探讨这个问题
重量级锁的释放大致可以分为两种场景:
Monitor中存在正在等待的其他线程,此时释放逻辑是先将Owner置为null,然后一般是从cxq或EntryList中取出一个线程并唤醒作为候选,候选竞争成功后才作为新的Owner。注意是单一唤醒而不是群体唤醒,具体策略取决于QMode,一般是取出EntryList的队首线程。Monitor中已经不存在正在等待的其他线程,此时释放逻辑是Owner置为null就直接结束重量级锁的释放逻辑。1
2
3
4
5
6
7
8
9// ObjectMonitor::exit
// 释放锁,将 owner 置为 NULL
OrderAccess::release_store_ptr (&_owner, NULL);
OrderAccess::storeload();
// 如果 EntryList 和 cxq 中均没有等待的线程,直接 return 退出
if ((intptr_t(_EntryList)|intptr_t(_cxq)) == 0 || _succ != NULL) {
TEVENT (Inflated exit - simple egress);
return;
}
也就是说,重量级锁的释放方法 ObjectMonitor::exit 中,并没有包含对象 markword 恢复到无锁状态的逻辑。
其实对象恢复到无锁状态的逻辑,是在锁的撤销膨胀逻辑中实现的,撤销膨胀操作发生在 safepoint。
safepoint 是一个所有 Java 线程都暂停执行的点,系统可以执行一些必须在所有线程都暂停时才能做的任务(比如某些 GC 任务,之前提到的偏向锁撤销等),SafepointSynchronize::do_cleanup_tasks 描述了在 safepoint 期间执行的一系列任务,其中就包括 ObjectSynchronizer::deflate_idle_monitors。
ObjectSynchronizer::deflate_idle_monitors 被调用时,它会遍历所有存在的 Monitor,查找那些空闲的 monitor,并分别调用 ObjectSynchronizer::deflate_monitor 完成具体的撤销膨胀操作。
当与锁对象关联的 Monitor 被 deflate 时,系统会将存放在 Monitor 的 header 中锁对象的原始的 markword 头部信息取出,重新设置到锁对象的对象头的 markword 上,从而锁对象恢复到无锁状态。相关源码如下:
1 | // ObjectSynchronizer::deflate_monitor |